Installing hadoop on MAC OS M1
M1 맥북에서 하둡 환경을 구성하다보니 수많은 블로그를 참고하였고, 설명이 제각각이라 그대로 따라만 하면 설치할 수 있도록 정리해보았습니다.
1. Java JDK 설치
Java JDK는 intel용을 설치하면 로제타2를 통해 돌아가므로
M1칩에서 네이티브로 돌아가는 Azul의 OpenJDK(download)를 설치하면 됩니다.
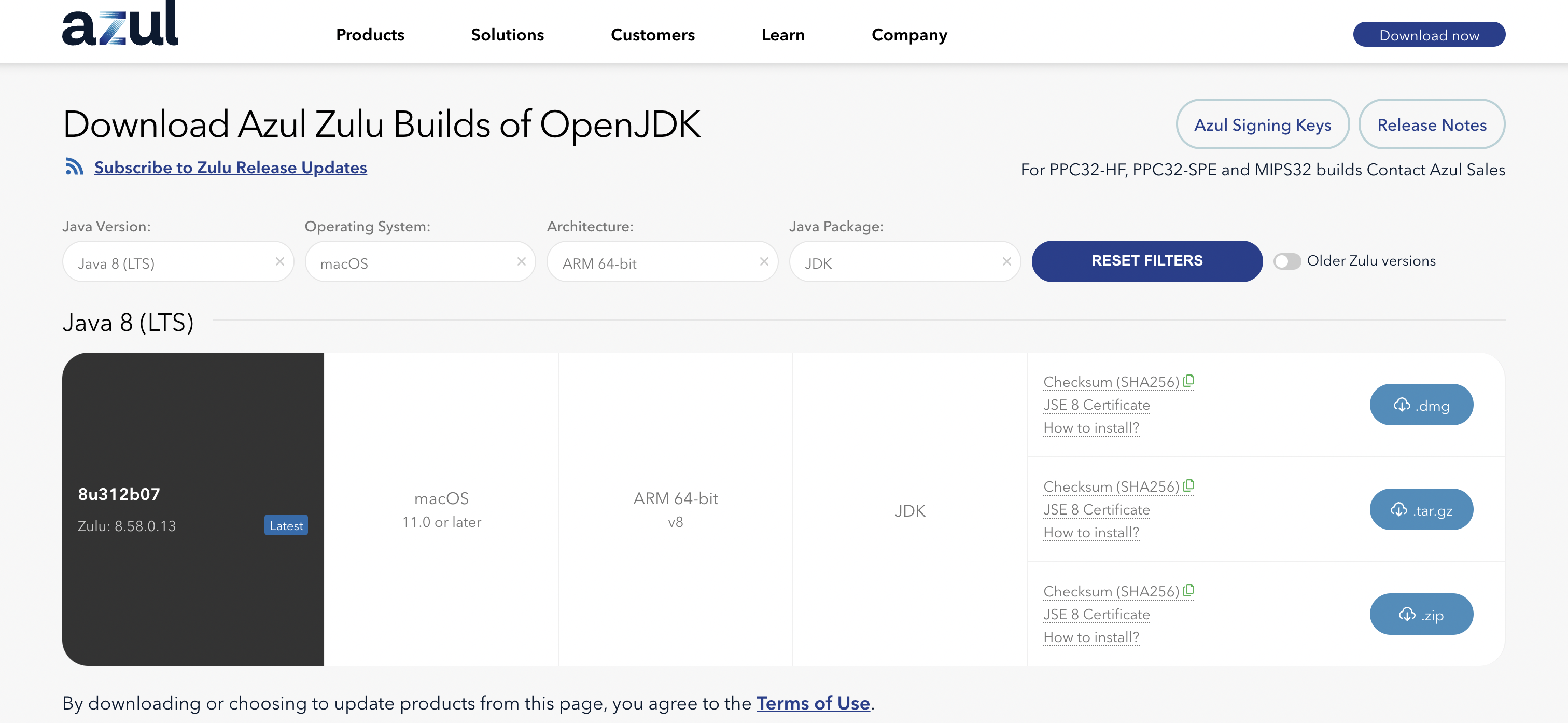
java-8 lts / mac os / arm64 옵션이 맞는지 확인하고나서 .tar.gz 파일을 다운받고, 다운받은 파일을 더블클릭하여 실행시키면 설치가 진행됩니다.
이후에 터미널창을 열고 아래와 같이 Java path를 설정하시면 됩니다.
1 | cd ~ |
java -version을 입력했을때 아래와 비슷한 결과가 나오면 제대로 설치된것입니다.
1 | cpprhtn@cpprhtn-MacBookPro ~ % java -version |
2. Hadoop을 구축할 계정 생성
하둡을 구축할 계정을 생성할 것입니다.
여러분이 현재 작업하던 환경과 같은 공간에서 하둡 환경을 구축하다가 예상치 못한 일이 발생했을때 복구하기 어려우므로 새로운 환경에서 환경을 구축하는 것입니다.
먼저 시스템 환경설정 -> 사용자 및 그룹에 들어와 자물쇠를 풀어줍니다.
이후 ‘+’ 버튼을 눌러 사용자 계정을 하나 만들어줍니다.
여러분이 만든 사용자에 대하여 사용자를 이 컴퓨터의 관리자로 허용을 체크하여 관리자권한을 부여합니다. 관리자 권한을 주지 않으면 이후에 하둡 파일을 수정할때 접근권한이 없다고 뜹니다.
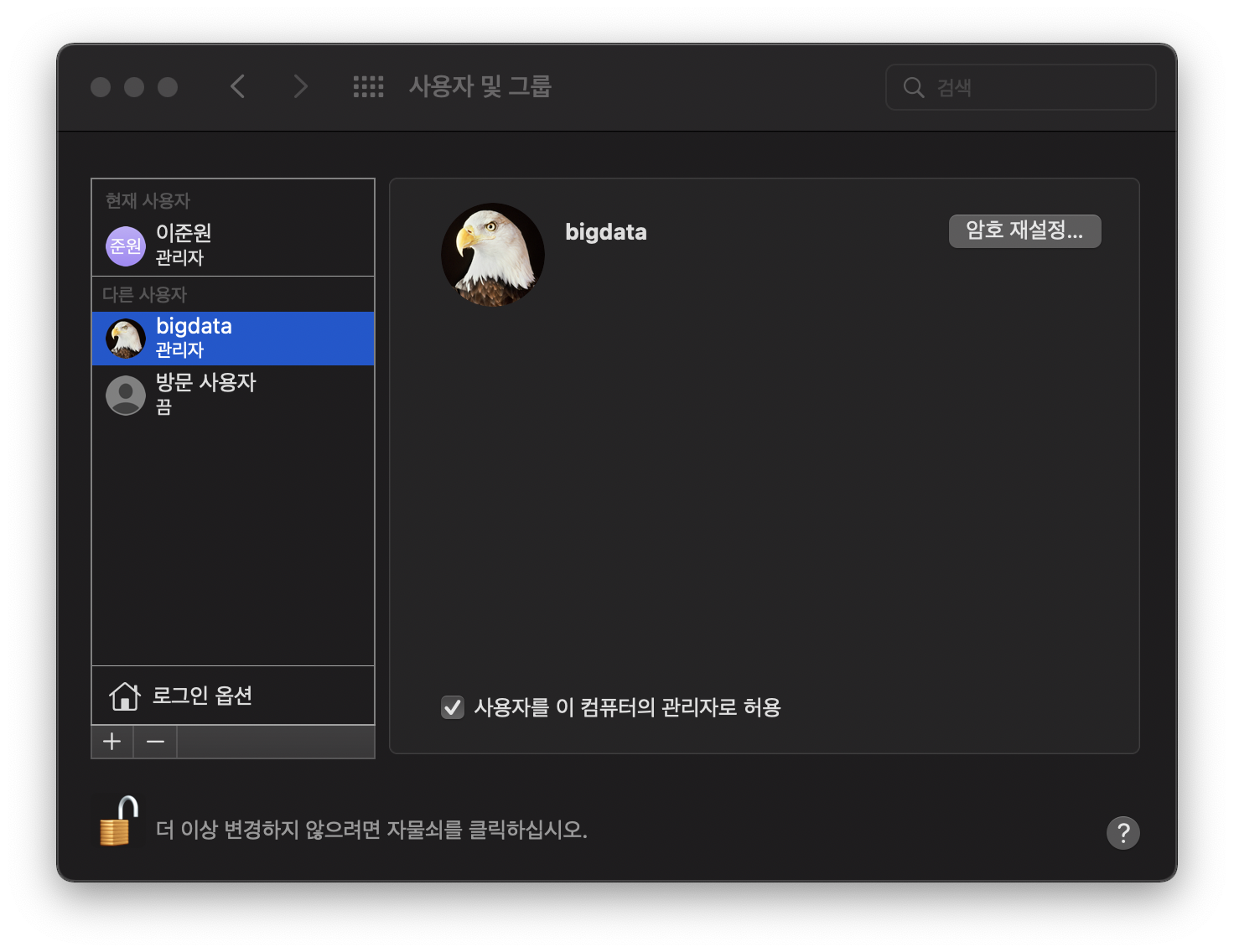
아직 재부팅에 들어가지 마세요
바로 이어서 시스템 환경설정 -> 공유에 들어와 원격 로그인버튼을 체크해줍니다.
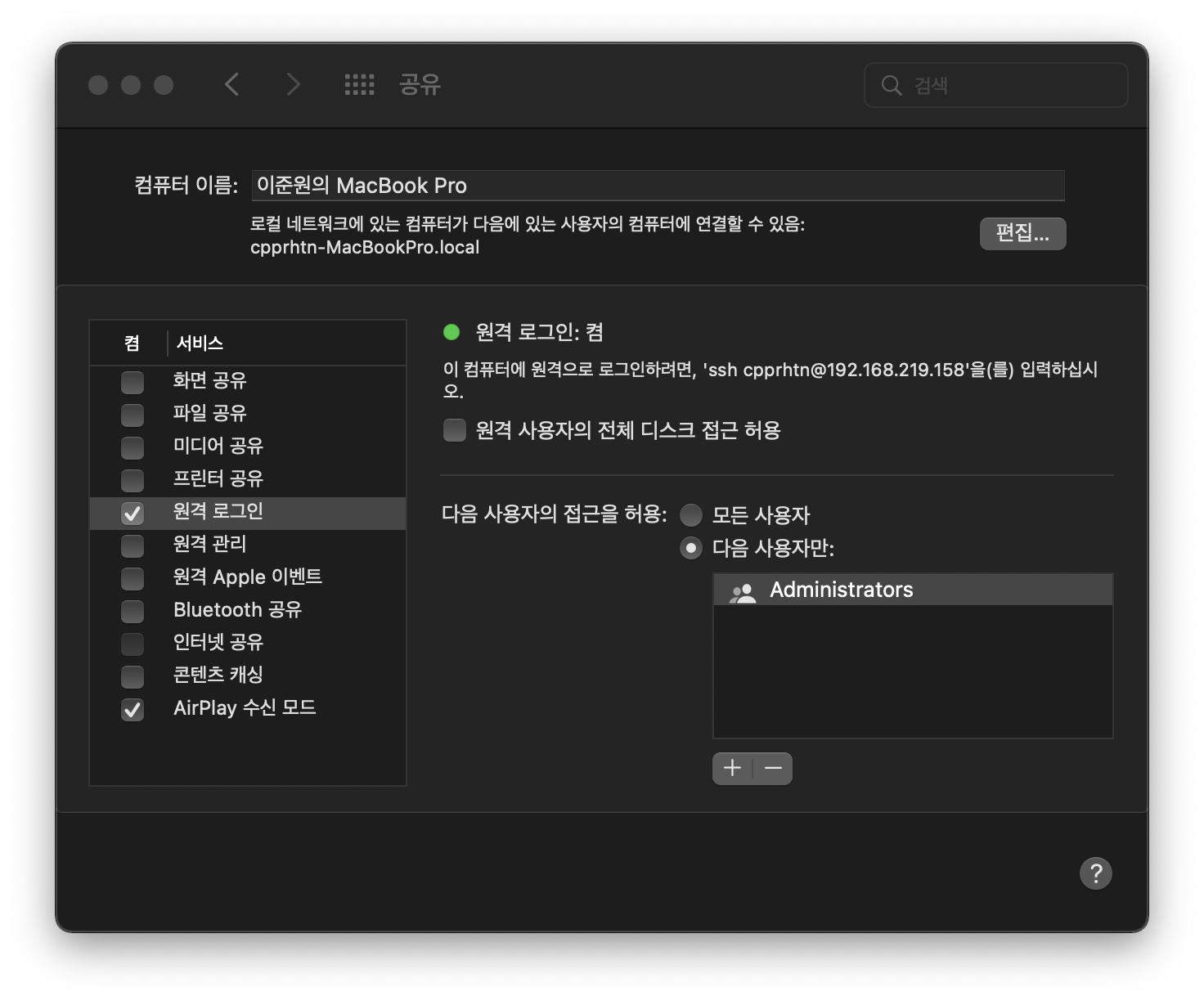
이제 시스템을 재부팅해 줄것인데, 여러분이 원래 작업하던 계정으로 다시 로그인하여 터미널을 오픈합니다.
새로 만들어준 계정으로 로그인 X
현재 사용하는 계정에서 새로 만든 계정으로 로그인합시다.
1 | su [새 계정] |
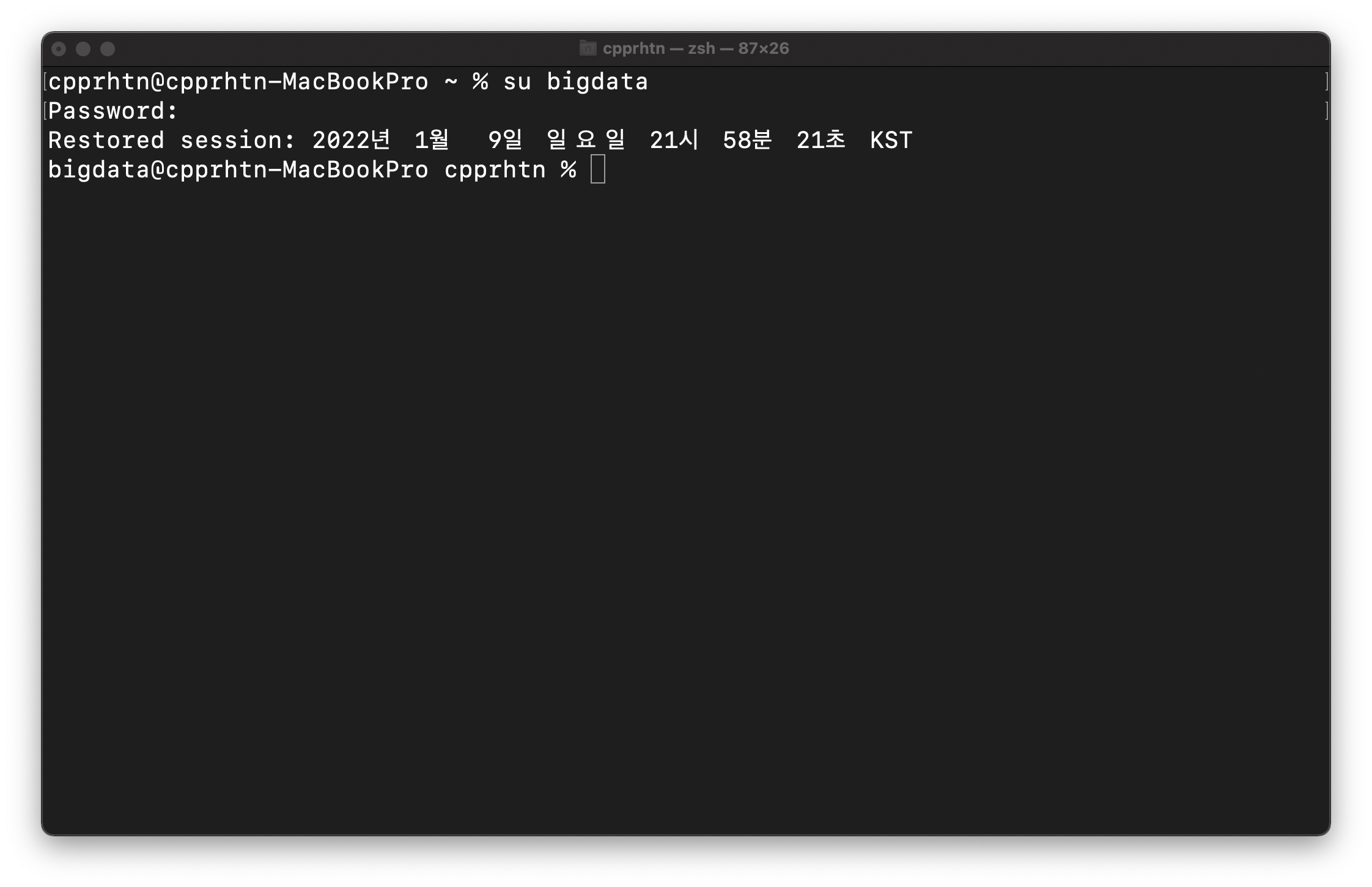
3. SSH 활성화
로컬 호스트에 SSH로 연결할 수 있도록 보안 키를 만들고 암호없이 사용할 수 있도록 키를 복사하여 권한을 제한해줍니다.
1 | # 새 계정의 home 디렉토리로 이동 |
4. Apache Hadoop 설치
하둡을 설치할텐데, 두가지 방법으로 설치가 가능합니다.
- 직접 다운받은후 경로 이동
Hadoop page에서 binary-aarch64 파일을 다운로드합니다.
다운받은 파일을 더블클릭하여 압축을 풀어줍니다.
압축이 풀린 파일을 새 계정의 home 디렉토리로 이동시켜줍니다.
1 | mv /Users/원래계정명/Downloads/hadoop-3.3.1 ~/ |
- homebrew의 wget를 이용하여 간편설치
homebrew가 설치되어있는 사람은 아래 코드를 이용하여 바로 설치가 가능합니다.
homebrew를 설치했고 잘 쓰고계시던 분들이 있을것입니다. 하지만 해당 포스트를 따라하면 새 계정을 만들어 작업하므로 새 게정의 home path의 .zshrc파일에서 homebrew path 설정이 안되어있을것입니다. 이런 경우에는 새 터미널 창을 하나켜서 본래 계정의 homebrew path를 카피하여 추가해주시기를 바랍니다.
필자의 path는 아래와 같으며 여러분들도 이와 비슷한 경로일 것입니다.
1 | export PATH=/opt/homebrew/bin:$PATH |
1 | # 다운로드 |
5. Hadoop setting
local에서 하둡을 세팅하기 위해서는 몇가지 파일을 수정해주어야합니다.
먼저 .zshrc 파일을 수정해줍니다.
1 | cd ~ |
.zshrc에 추가되는 파일의 첫번째 export 라인의 path는 꼭 수정해줍시다. (새 계정명으로)
hadoop-env.sh 파일 편집
이후 hadoop-env.sh 파일에서 아래와 같이 주석되어있는부분을 주석을 해제하고 JAVA_HOME path를 세팅해줍니다.
export JAVA_HOME=
필자는 ~/.zshrc에서 이미 세팅해두었기때문에 해당 파일은 추가코드 없이 그냥 넘어갔습니다.
1 | vi $HADOOP_HOME/etc/hadoop/hadoop-env.sh |
core-site.xml 파일 편집
HDFS와 하둡의 핵심 속성을 정의해줍니다.
새 계정 이름으로 경로를 설정해줍시다.
1 | vi $HADOOP_HOME/etc/hadoop/core-site.xml |
hdfs-site.xml 파일 편집
hdfs-site.xml 파일은 노드 메타데이터, fsimage 파일 및 편집 로그 파일을 저장할 위치를 제어합니다.
NameNode 및 DataNode 스토리지 디렉토리를 정의합니다.
새 계정 이름으로 경로를 설정해줍시다.
value값에 설정된 숫자는 1~3으로 설정됩니다.
1은 로컬환경, 2는 가상 분할환경, 3은 완전 분할환경을 의미합니다.
이 포스트에서는 로컬환경을 구축하고 있으므로 value값은 1을 부여하였습니다.
1 | vi $HADOOP_HOME/etc/hadoop/hdfs-site.xml |
mapred-site.xml 파일 편집
MapReduce 값을 정의할 수 있습니다.
MapReduce 프레임워크 이름을 지정해주었습니다.
1 | vi $HADOOP_HOME/etc/hadoop/mapred-site.xml |
yarn-site.xml 파일 편집
여기에는 노드 관리자, 리소스 관리자, 컨테이너 및 애플리케이션 마스터에 대해 설정해줍니다.
코드가 길어도 수정할 부분은 없으니 복붙하여 쓰시면 될듯합니다.
1 | vi $HADOOP_HOME/etc/hadoop/yarn-site.xml |
6. HDFS namenode format
Hadoop 서비스를 처음 시작하기 전에 namenode를 포맷하는 것이 중요합니다.
1 | cd ~ |
7. Hadoop 시작
이전에 .zshrc에서 경로세팅을 했으므로 홈 디렉토리에서 아래와 같은 코드를 이용하여 하둡 서비스를 실행 및 종료 시킬 수 있습니다.
1 | cd ~ |
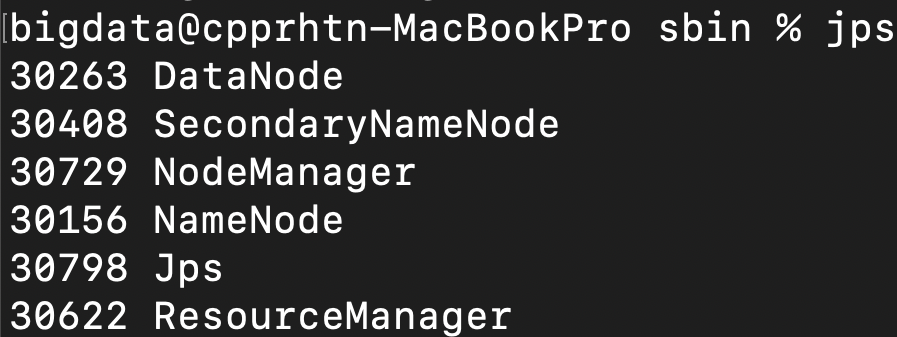
우선은 start-all.sh을 실행시킨 후 10초정도 기다리면 하둡 구성요소들이 작동됩니다.
이후에 jps명령을 실행시키면 아래 사진과 같이 최소한 6개의 서비스가 표시되어야 합니다.
(표시되는 순서나 넘버는 상관없음)
8. 브라우저에서 Hadoop UI에 액세스
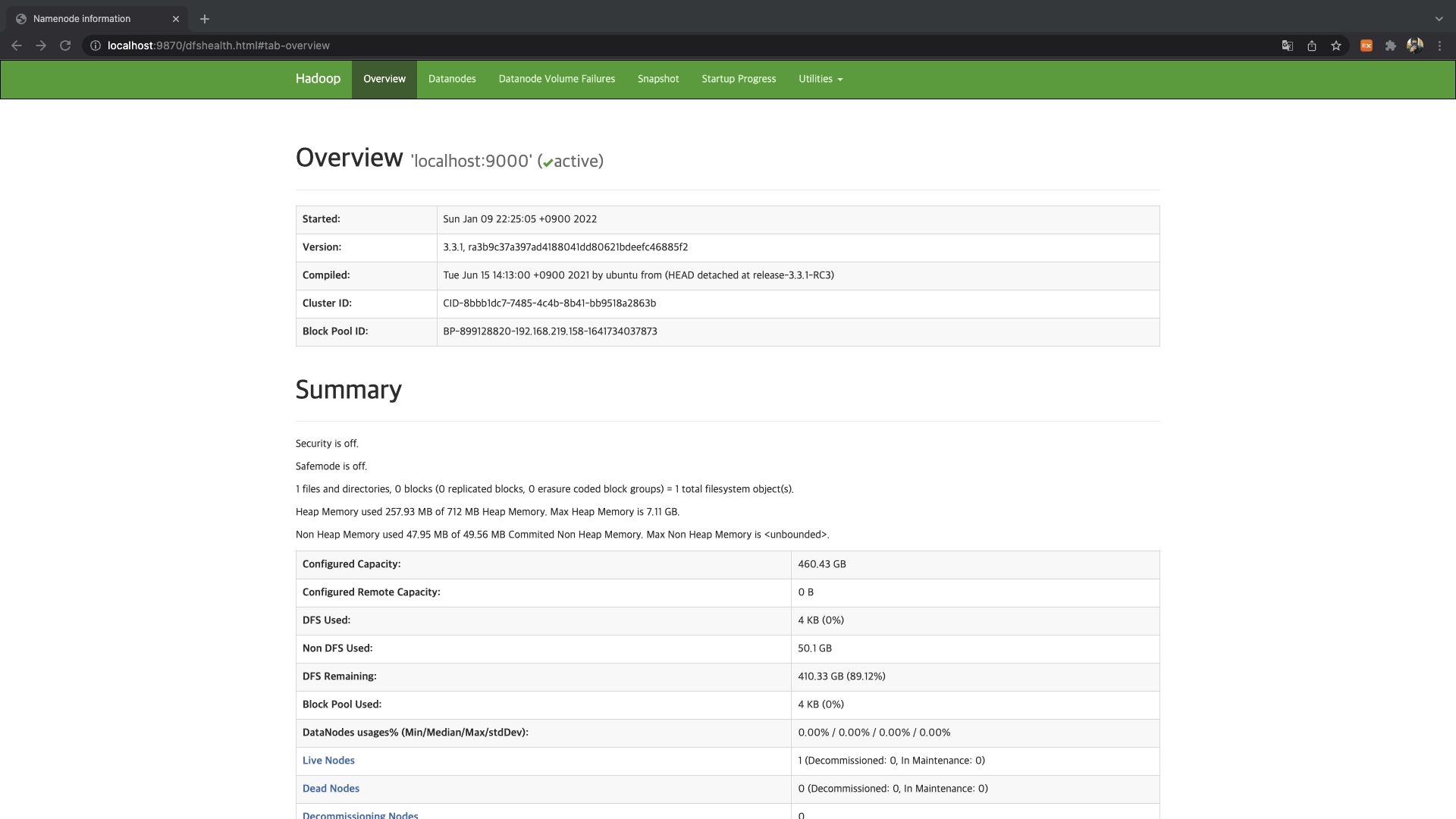
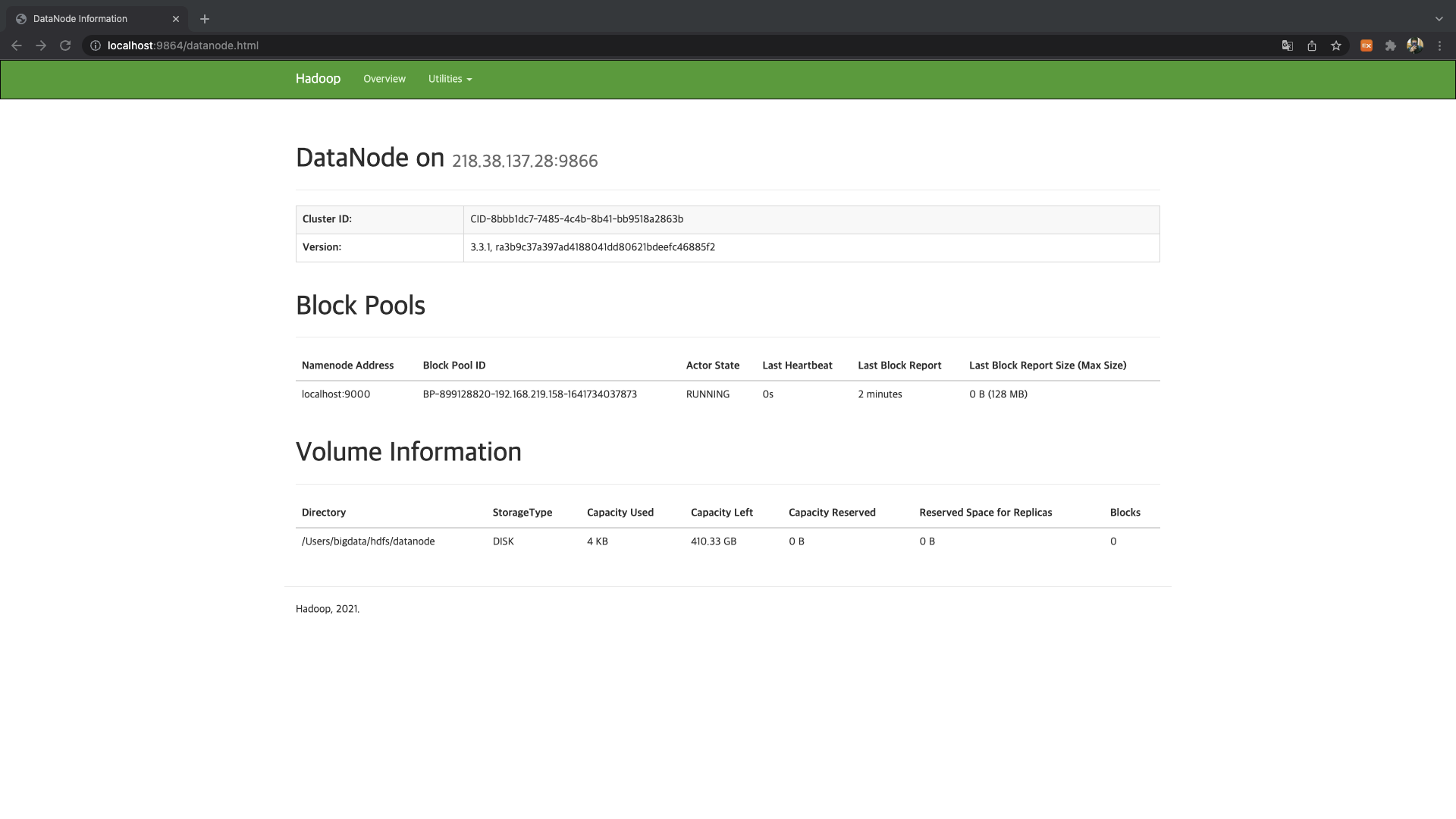
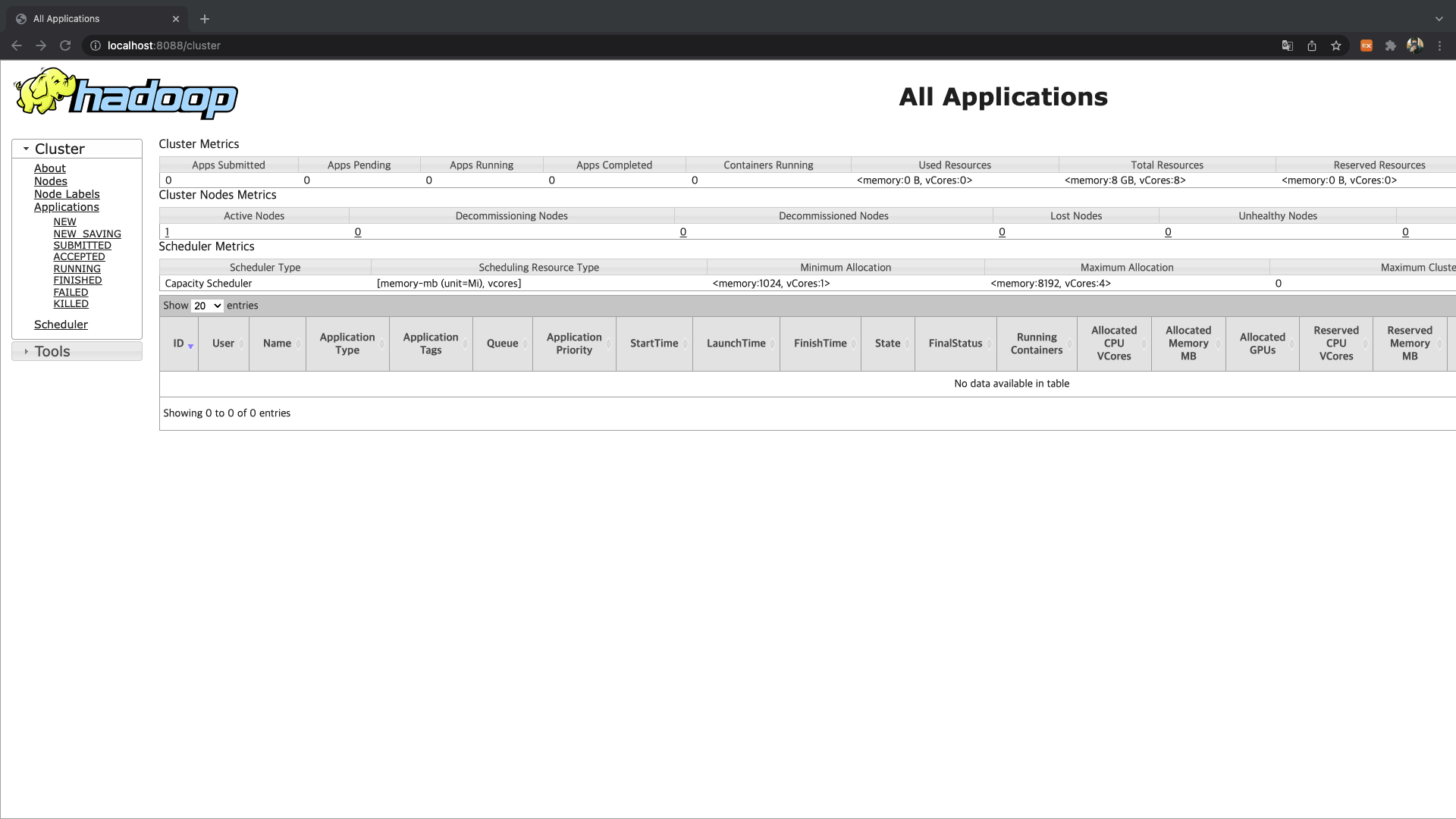
인터넷 브라우저를 열은 후에 localhost URL로 이동한 후 포트 번호를 사용하여 Hadoop UI에 접근할 수 있습니다.
- 9870 : NameNode 사용자 인터페이스 [전체 클러스터에 대한 포괄적인 개요를 제공]
- 9864 : DataNode 사용자 인터페이스 [브라우저에서 직접 개별 DataNode에 접근하는데 사용]
- 8088 : YARN Resource Manager [하둡 클러스터에서 실행 중인 모든 프로세스를 모니터링 할 수 있음]
Installing hadoop on MAC OS M1
https://cpprhtn.github.io/2022/01/09/Installing-Hadoop-in-mac/