HDFS란?
HDFS(Hadoop Distributed File System)는 수십 테라바이트 이상의 대용량 파일을 분산된 서버에 저장하고, 많은 클라이언트가 저장된 데이터를 빠르게 처리할 수 있게 설계된 파일 시스템입니다.
1. HDFS란?
기존에도 DAS, NAS, SAN과 같은 대용량 파일 시스템이 있었으나 HDFS와 기존 대용량 파일 시스템의 가장 큰 차이점은 저사양 서버를 이용해 스토리지를 구성할 수 있다는 것입니다.
HDFS를 사용하면 고사양 서버에 비해 매우 저렴한 저사양 서버 수십, 수백대를 묶어서 하나의 스토리지처럼 사용할 수 있으며 물리적으로는 분산된 서버의 로컬 디스크에 저장되어있지만 HDFS에서 제공하는 API를 이용하여 파일의 읽기 및 저장을 마치 한 서버에서 작업하듯이 구성할 수 있습니다.
그렇다고 HDFS가 기존 대용량 파일 시스템을 완전히 대체하는 것은 아닙니다.
고성능, 고가용성이 필요한 경우에는 SAN을, 안정적인 파일 저장이 필요한 경우에는 NAS를 사용합니다.
또한 트랜잭션이 중요한 경우에도 HDFS가 적합하지 않으며, 대규모 데이터를 저장하거나, 배치로 처리를 하는 경우에 HDFS를 사용하면 됩니다.
HDFS를 만든이유
HDFS는 네 가지 목표를 가지고 설계되었습니다.
- 장애 복구
서버에는 다양한 장애가 발생할 수 있습니다. 이러한 서버를 수십, 수백대를 묶어서 구축한 분산 서버에는 당연히 장애가 생길 확률이 높아집니다.
HDFS는 이러한 장애를 빠른 시간에 감지하고 대처할 수 있게 설계되어 있습니다.
- 스트리밍 방식의 데이터 접근
HDFS는 클라이언트의 요청을 빠른 시간 내에 처리하는 것보다는 동일한 시간 내에 더 많은 데이터를 처리하는 것을 목표로 합니다.
이를 위해 HDFS는 랜덤 접근 방식 대신 스트리밍 방식으로 데이터에 접근하도록 설계되어 있습니다.
- 대용량 데이터 저장
HDFS는 파일 하나의 크기가 테라바이트 이상의 크기로도 저장될 수 있게 설계되었습니다. 따라서 높은 데이터 전송 대역폭과, 하나의 클러스터에서 수백 대의 노드를 지원 할 수 있습니다. 또한 하나의 인스턴스에서는 수백만개 이상의 파일을 지원합니다.
- 데이터 무결성
HDFS에서는 한번 저장한 데이터는 더이상 수정할 수 없고, 읽기만 가능하게 하여 무결성을 유지했습니다. 하지만 데이터 수정이 불가능하다는 것은 ㅋ 하둡 초기에서부터 검토되어 왔고, 하둡 2.0 버전부터는 HDFS에 저장된 파일에 append 기능이 추가되었습니다.
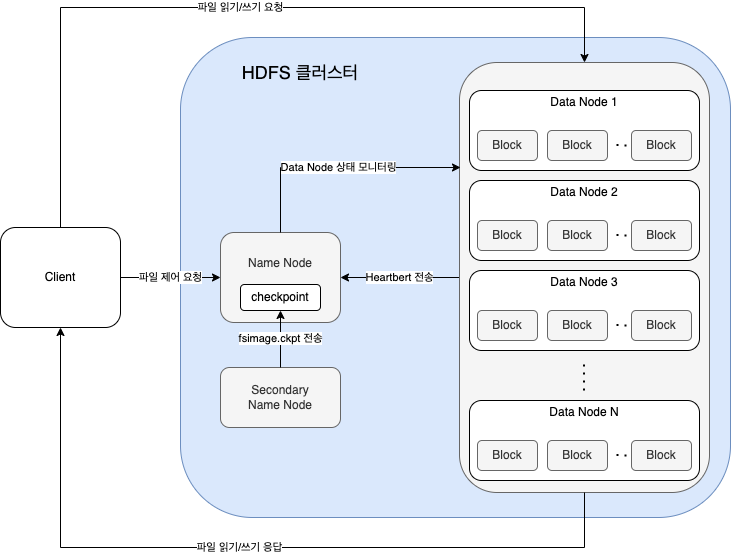
HDFS 아키텍처
- 블록 구조 파일 시스템
HDFS는 블록 구조의 파일 시스템입니다. HDFS에 저장하는 파일은 특정 크기의 블록으로 나눠져 분산된 서버에 저장합니다. 하둡의 버전에 따라서 블록 크기의 defalt 세팅값이 달라지는데, 하둡 2.0 이상버전에서는 블록당 128MB의 크기를 가지고 있습니다. 따라서 예를 들어 200MB 파일이 있다면 128MB 블록 2개를 사용하게 되며, 블록 하나는 128MB를 전부 사용하게 되며, 다른 블록하나는 128MB를 다 차지하는 것이 아니라 78MB를 차지하게 되는 형태입니다. 그렇기 때문에 데이터 크기에 상관없이 저장할 수 있습니다.
또한 HDFS에서는 기본적으로 3개의 블록 복제본을 저장하게 됩니다. 이는 특정 서버의 하드디스크에 오류가 생기더라도 복제된 블록을 사용하여 데이터를 조회할 수 있습니다. 블록의 크기와 복제본의 수는 하둡 환경설정 파일에서 변경할 수 있습니다.
- 네임노드와 데이터노드
네임노드
네임노드는 다음과 같은 기능을 합니다.
메타데이터 관리
네임노드는 파일 시스템을 유지하기 위한 메타데이터를 관리합니다. 메타데이터는 파일시스템 이미지와 파일에 다한 블록 매핑 정보로 구성됩니다.데이터노드 모니터링
데이터노드가 네임노드에게 3초마다 heartbeat 메시지를 전송합니다. heartbeat는 데이터노드 상태 정보와 block-report로 구성됩니다. 네임노드는 heartbeat를 이용하여 데이터노드의 실행 상태와 용량을 모니터링합니다. 일정 시간 내에 heartbeat 메시지가 들어오지않는 데이터노드가 있을 경우 장애가 발생한 서버로 판단합니다.블록 관리
데이터노드에 장애가 발생시 해당 데이터노드의 블록을 새로운 데이터노드로 복제합니다. 용량이 부족한 데이터노드가 있다면 여유있는 데이터노드로 블록을 이동시킵니다. 블록의 복제본 수 또한 관리합니다.클라이언트 요청 접수
클라이언트가 HDFS에 접근하려면 반드시 네임노드에 접속해야합니다. HDFS에 파일을 저장하는 경우 기존 파일의 저장 여부와 권한 확인 절차를 거쳐서 저장을 승인합니다. 또한 파일을 조회하는 경우에는 블록의 위치 정보를 반환합니다.
데이터노드
데이터노드는 클라이언트가 HDFS에 저장하는 파일을 로컬 디스크에 유지합니다. 이때 로컬 디스크에 저장되는 파일은 두 종류로 구성됩니다.
첫 번째 파일은 실제 데이터가 저장되어 있는 로우 데이터이며, 두 번째 파일은 체크섬이나 파일 생성 일자와 같은 메타데이터가 설정되어 있는 파일입니다.
보조네임노드
- 네임노드
네임노드는 메타데이터를 메모리에서 처리합니다. 하지만 메모리에만 데이터를 유지할 경우 서버가 재부팅되면 모든 메타데이터를 유실할 수 있습니다. HDFS에서는 이러한 문제점을 해결하기 위해 editslog와 fsimage라는 두 개의 파일을 생성합니다.
editslog: HDFS의 모든 변경 이력을 저장한 파일.
fsimage: 메모리에 저장된 메타데이터의 파일 시스템 이미지를 저장한 파일.
네임노드 작동시
- 네임노드가 구동되면 로컬에 저장된 fsimage와 editslog를 조회
- 메모리에 fsimage를 로딩해 파일시스템 이미지를 생성
- 메모리에 로딩된 파일 시스템 이미지에 editslogdp 기록된 변경 이력을 적용
- 메모리에 로딩된 파일 시스템 이미지를 이용해 fsimage 파일을 갱신
- editslog 초기화
- 데이터노드가 전송한 플록리포트를 메모리에 로딩된 파일 시스템 이미지에 적용
보조네임노드
editslog는 별도의 크기제한이 없기때문에 무한대로 커질 수 있기 때문에 editslog의 크기가 계속해서 커지면 위 단계중 3번 단계를 진행할 때 많은 시간이 소요될 것입니다.
이러한 문제점을 해결하기 위해 HDFS는 보조네임노드라는 노드를 제공합니다.
보조네임노드는 주기적으로 네임노드의 fsimage를 갱신하는 역할을 하며, 이러한 작업을 체크포인트라고 합니다.
보조네임노드는 다음과 같은 체크포인팅 단계를 거쳐 네임노드의 fsimage를 갱신해줍니다.
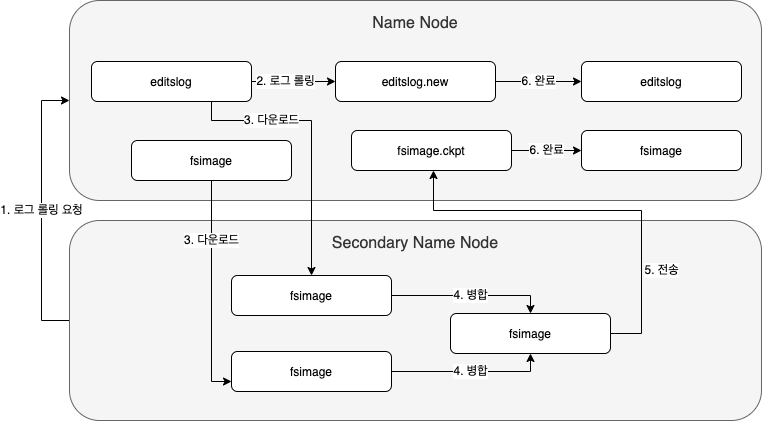
이렇게 체크포인팅이 완료되면 네임노드의 fsimage는 최신 내역으로 갱신되며, editslog의 크기도 축소됩니다.
기본적으로 한시간마다 체크포인팅이 발생하며, 하둡 환경설정 파일에서 변경할 수 있습니다.
- 보조네임노드도 중요하다
보조네임노드를 중요하게 생각하지 않거나 보조네임노드를 네임노드의 백업 노드라고 생각할 수도 있습니다. 하지만 앞에서 설명했듯이 보조네임노드는 네임노드의 (fsimage 갱신, editslog 축소) 시켜주는 역할을 하므로 백업과는 관련이 없습니다.
또한 보조네임노드가 다운되어있어도 네임노드의 동작에는 전혀 문제가 없기때문에 보조네임노드를 방치해둘지도 모릅니다.
하지만 네임노드를 재구동하는 상황이 생겼을때, editslog의 크기가 너무 커서 네임노드의 메모리에 로딩되지 못하는 상황이 발생할 수 있습니다. 따라서 이러한 장애를 사전에 방지하기 위해서는 주기적으로 보조네임노드를 관리해주어야 합니다.
HDFS Architecture