맵리듀스란?
맵리듀스는 HDFS에 저장된 파일을 분산 배치 분석을 할 수 있게 도와주는 프레임워크입니다. 개발자는 맵리듀스 프로그래밍 모델에 맞게 애플리케이션을 구현하고, 데이터 전송, 분산 처리, 내고장성 등의 복잡한 처리는 맵리듀스 프레임워크가 자동으로 처리해줍니다.
맵리듀스의 개념
맵리듀스(MapReduce) 모델은 맵(Map)과 리듀스(Reduce)라는 두 가지 단계로 데이터를 처리합니다.
- Map : 입력 파일을 한 줄씩 읽어서 데이터를 변형(transformation)
- 데이터 변형 규칙은 자유롭게 정의가 가능
- 출력 또한 한 줄에 하나의 데이터가 출력
- Reduce : Map의 결과 데이터를 집계(aggregation)
맵리듀스 프로그래밍
맵리듀스 프로그래밍은 다음과 같은 함수로 표현됩니다.
Map : (key1, value1) -> list(key2, value2)
- 맵은 키(1)와 값(1)으로 구성된 데이터를 입력받아 이를 가공하고 분류한 후, 새로운 키(2)와 값(2)으로 된 리스트를 출력합니다.
- 이를 여러번 수행하면 새로운 키를 가진 여러개의 데이터가 생깁니다.
Reduce : (key2, list(value2)) -> (key3, list(value3))
- 리듀스는 새로운 키(2)로 그룹핑된 값(2)의 리스트를 입력데이터로 전달받습니다. 그리고 값의 리스트에 대한 집계 연산을 실행해 새로운 키(3)로 그룹핑된 새로운 값(3)의 리스트를 생성합니다.
MapReduce Architecture
맵리듀스 프레임워크는 개발자가 분석 로직을 구현하는 데 집중하도록 돕고, 데이터에 대한 분산과 병렬 처리를 전담합니다.
System configuration
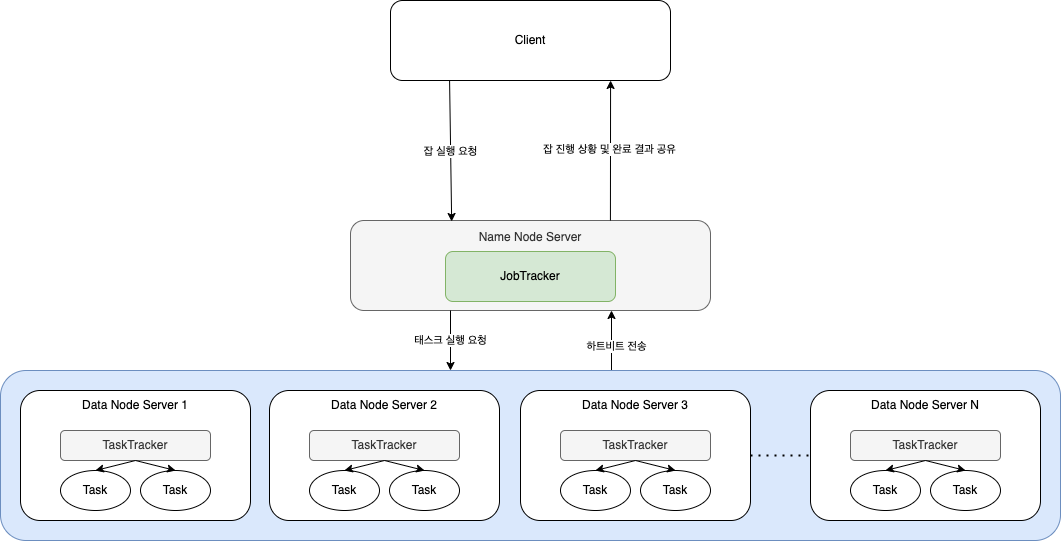
클라이언트
클라이언트는 사용자가 실행한 맵리듀스 프로그램과 하둡에서 제공하는 맵리듀스 API를 의미합니다. 사용자는 맵리듀스 API로 맵리듀스 프로그램을 개발하고, 개발한 프로그램을 하둡에서 실행할 수 있습니다.클라이언트가 하둡으로 실행을 요청하는 맵리듀스 프로그램은 잡이라는 하나의 작업 단위로 관리됩니다.
잡트래커
잡트래커는 하둡 클러스터에 등록된 전체 잡의 스케줄링을 관리하고 모니터링합니다. 전체 하둡 클러스터에서 하나의 잡트래커가 실행되며 보통 하둡의 네임노드 서버에서 실행됩니다.사용자가 새로운 잡을 요청하면 잡트래커는 잡을 처리하기 위해 필요한 맵과 리듀스의 실행량을 계산합니다. 이렇게 계산된 맵과 리듀스를 어떤 태스크트래커에서 실행할지 결정하고, 해당 태스크트래커에 잡을 할당합니다.
이때 태스크트래커는 잡트래커의 작업 수행 요청을 받아 맵리듀스 프로그램을 실행합니다. 잡트래커와 태스크트래커는 하트비트라는 메서드로 네트워크 통신을 하면서 태스크트래커의 상태와 작업 실행 정보를 주고받게 됩니다. 만약 태스크트래커에 장애가 발생하면 잡트래커는 다른 대기 중인 태스크트래커를 찾아 태스크를 재실행합니다.
태스크트래커
태스크트래커는 사용자가 설정한 맵리듀스 프로그램을 실행하며, 하둡의 데이터노드에서 실행되는 데몬입니다. 태스크트래커는 잡트래커의 작업을 요청받고, 잡트래커가 요청한 맵과 리듀스 개수만큼 맵 태스크와 리듀스 태스크를 생성합니다. 여기서 맵 태스크와 리듀스 태스크는 사용자가 설정한 맵과 리듀스 프로그램을 의미합니다.맵 태스크와 리듀스 태스크가 완성되면 새로운 JVM을 구동해 맵 태스크와 리듀스 태스크를 실행합니다. 이때 태스크를 실행하기 위한 JVM은 재사용할 수 있게 설정할 수 있습니다. 서버가 부족해서 하나의 데이터노드를 구성했더라도 여러 개의 JVM을 실행해 데이터를 동시에 분석하므로 병렬 처리 작업에 문제가 없습니다.
Data flow
1. 맵 단계
맵 단계에서는 입력 파일을 읽어 맵의 출력 데이터를 생성하는 단계입니다.
아래와 같은 아키택처를 가지고 있으며 다음 순서에 따라 처리됩니다.
스플릿 : 맵리듀스는 HDFS에 저장된 파일을 읽어서 배치 처리를 합니다. 맵리듀스 프레임워크는 이러한 대용량 파일을 처리하기 위해 입력 데이터 파일을 입력 스플릿이라는 고정된 크기의 조각들로 분리합니다. 입력 스플릿별로 하나의 맵 태스크가 생성되며 각 입력 스플릿은 맵 태스크의 입력 데이터로 전달됩니다. 여기서 입력 스플릿은 HDFS 블록 크기 기준으로 생성됩니다. 따라서 현재 시점에서는 128MB 단위로 입력 스플릿이 생성될 것 입니다.
레코드 읽기 : 맵 태스크는 입력 스플릿의 데이터를 레코드 단위로 읽어서 사용자가 정의한 맵 함수를 실행합니다. 이때 맵 태스크의 출력 데이터는 태스크트래커가 실행되는 서버의 로컬 디스크에 저장되며, 맵의 출력키를 기준으로 정렬됩니다. HDFS에 저장하지 않는 이유는 맵 태스크의 출력 데이터는 중간 데이터라서 영구적으로 보관할 필요가 없기 때문이며, 잡이 완료될 경우 중간 데이터는 모두 삭제됩니다.
2. 셔플 단계
리듀스 태스크는 맵 태스크의 출력 데이터를 내려받아 연산을 수행해야 합니다. 맵리듀스 프레임워크는 이러한 작업이 진행될 수 있게 셔플을 지원합니다.
셔플은 맵 태스크의 출력 데이터가 리듀스 태스크에게 전달되는 일련의 과정을 의미하며, 다음 순서에 따라 진행됩니다.
파티셔너는 맵의 출력 레코드를 읽어서 출력키의 해시값을 구합니다. 각 해시값은 레코드가 속하는 파티션 번호로 사용됩니다. 파티셔는 실행될 리듀스 태스크 개수만큼 생성됩니다.
파티셔닝 된 맵의 출력 데이터는 네트워크를 통해 리듀스 태스크에 전달됩니다. 하지만 모든 맵의 출력이 동시에 완료되지 않기 때문에 리듀스 태스크는 자신이 처리할 데이터가 모일 때까지 대기합니다. 리듀스 태스크는 맵의 출력 데이터가 모두 모이면 데이터를 정렬하고, 하나의 입력 데이터로 병합합니다.
리듀스 태스크는 병합된 데이터를 레코드 단위로 읽어 들입니다.
3. 리듀스 단계
리듀스 단계에서는 사용자에게 전달할 출력 파일을 생성합니다.
다음과 같은 두 단계를 따릅니다.
리듀스 태스크는 사용자가 정의한 리듀스 함수를 레코드 단위로 실행합니다. 이때 리듀스 태스크가 읽어 들이는 데이터는 입력키와 입력키가 해당하는 입력값의 목록으로 구성됩니다. 위 예제의 리듀스 함수는 입력키별로 입력값의 목록을 합산해서 출력합니다. 이때 출력 데이터는 출력키와 출력값의 쌍으로 구성됩니다.
리듀스 함수가 출력한 데이터는 HDFS에 저장됩니다. HDFS에는 리듀스 개수만큼 출력 파일이 생성되며, 파일명은
part-nnnnn으로 설정됩니다. 여기서 nnnnn은 파티션 번호를 의미하며, 00000부터 1씩 증가합니다.